※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. ※

오늘은 검색 알고리즘인 BM25와 벡터 기반 검색, 그리고 두 가지를 조합한 앙상블 리트리버를 실습했습니다.
이번 글에서는 BM25의 개념부터 LangChain 실습 과정까지 배운 내용을 정리하겠습니다 😉
📚 BM25, 왜 중요할까?
BM25는 사용자가 특정 단어를 검색했을 때 어떤 문서가 더 적합한지 결정하는 전통적인 정보검색 알고리즘입니다.
1️⃣ 단어 빈도 (TF)
BM25는 문서 안에 특정 단어가 많이 등장할수록 그 문서는 해당 주제와 관련이 높다고 판단합니다.
2️⃣ 역문서 빈도 (IDF)
너무 흔한 단어(예: 그리고, 또한)는 점수를 낮게, 드물고 중요한 단어(예: 인공지능, 머신러닝)는 점수를 높게 부여합니다.
3️⃣ 문서 길이 보정
같은 단어 빈도라도 긴 문서보다 짧은 문서에서 등장할 때 더 높은 중요도를 부여합니다.
결국 BM25는 TF, IDF, 문서 길이를 조합해 가장 적합한 문서에 높은 우선순위를 부여하게 됩니다.
🔧 LangChain 실습: PDF 로딩부터 BM25 리트리버 적용까지
오늘 실습에서는 수업에서 참고한 삼성전자 기업분석 PDF 파일을 불러와 LangChain에서 활용을 했습니다.
✅ PyPDFLoader로 PDF 파일을 로드하고
✅ RecursiveCharacterTextSplitter로 문서를 청크(500자 단위)로 분할한 뒤
✅ BM25Retriever로 텍스트 기반 검색을 수행
🧪 BM25 + 벡터 검색 = 앙상블 리트리버
오늘의 하이라이트는 EnsembleRetriever(앙상블 리트리버)입니다.
1️⃣ BM25와 벡터 검색 각각의 검색 결과에서 상위 k개 문서를 가져오고
2️⃣ 각 점수에 가중치를 부여하여 중복 문서의 점수를 합산하고
3️⃣ 최종 점수 순으로 정렬해 Top-k 문서를 반환
예를 들어, BM25에서 A, B, C, D 문서가, 벡터 검색에서 A, B, E, F 문서가 나왔다면,
중복된 A, B 문서는 점수를 합산해 더 높은 순위로 올라갑니다.
이 방식은 키워드와 의미 유사성 양쪽에서 검증된 문서들을 강화하는 효과가 있습니다.
📌 오늘의 인사이트
- BM25는 전통적이지만 여전히 강력한 키워드 기반 검색입니다.
- 임베딩 기반 벡터 검색은 의미 유사성을 이해할 수 있다는 강점을 가집니다.
- 앙상블 리트리버는 두 접근법의 장점을 결합하여 RAG 시스템의 답변 품질을 한층 끌어올립니다.
① 오늘자 날짜, 공부 시작, 종료 시각 포함 사진 각 1장


② 1개 클립 수강 인증 사진 1장 / 학습 인증 사진 1장

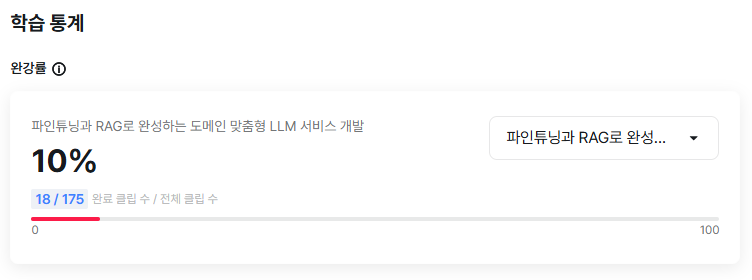
③ 챌린지 대상 강의 완강률 캡쳐 사진 1장
https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
'패스트캠퍼스환급챌린지' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 13일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (2) | 2025.07.13 |
|---|---|
| 패스트캠퍼스 환급챌린지 12일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (0) | 2025.07.12 |
| 패스트캠퍼스 환급챌린지 10일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (0) | 2025.07.10 |
| 패스트캠퍼스 환급챌린지 9일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.07.09 |
| 패스트캠퍼스 환급챌린지 8일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (0) | 2025.07.08 |