※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. ※

오늘은 LangChain을 활용해 RAG(Retrieval-Augmented Generation) 파이프라인을 처음부터 끝까지 구현해보았습니다.
PDF 문서를 불러와 분할하고, 임베딩하고, 벡터 DB에 적재한 뒤, LLM과 연결하여 답변까지 생성하는 과정을 직접 실습했습니다.
1️⃣ PDF 로딩 및 청킹(chunking)
강의에서 예시로 제공한 삼성전자 기업분석 PDF(27페이지)를 PyPDFLoader로 로드했습니다.
각 페이지를 500자 단위로 분할(Chunking)하기 위해 RecursiveCharacterTextSplitter를 사용했고, 이 과정에서 총 69개의 청크가 생성되었습니다.
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = PyPDFLoader('파일명.pdf')
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splited_docs = text_splitter.split_documents(pages)
2️⃣ 임베딩 및 벡터 DB 적재
허깅페이스에서 로드한 BAAI/bge-m3 모델로 각 청크를 임베딩하고 Chroma 라는 Vector DB에 그 결과를 적재했습니다.
임베딩 후 ‘삼성전자의 주요 사업영역은?’ 같은 질문으로 유사도 상위 4개 문서를 검색해보았습니다.
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
model_hf = HuggingFaceEmbeddings(model_name='BAAI/bge-m3')
db = Chroma.from_documents(splited_docs, model_hf)
docs = db.similarity_search('삼성전자의 주요 사업영역은?', k=4)
3️⃣ LLM(GPT-4o) 연동 및 Q&A 생성
GPT-4o를 LangChain의 RetrievalQA 체인과 연결해,
검색된 문서를 바탕으로 답변을 생성하는 챗봇(‘삼성맨’)을 만들었습니다.
검색 결과가 없을 땐 “답변할 수 없다”고 안내하도록 프롬프트를 설계했습니다.
from langchain_openai import ChatOpenAI
from langchain import PromptTemplate
from langchain.chains import RetrievalQA
template = """
당신은 삼성전자 기업 보고서를 설명해주는 챗봇 '삼성봇'입니다.
검색 결과에 없는 내용이라면 답변할 수 없다고 하세요. 이모지를 사용해 친근하게 답변하세요.
{context}
Question: {question}
Answer:
"""
prompt = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name='gpt-4o')
retriever = db.as_retriever(search_kwargs={"k": 3})
qa_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever, chain_type_kwargs={"prompt": prompt})
response = qa_chain.invoke("삼성전자의 주요 사업영역은?")
print(response['result'])- template에서 중괄호로 묶인, {context}와 {question}는 LangChain의 PromptTemplate에서 사용하는 변수 자리표시자(placeholder)입니다.
- {context}에서는 사용자 질문과 관련해 검색된 문서들의 요약 또는 원문이 들어가게 되고, {qeustion}에서는 사용자 질문이 들어갑니다.
- 앞서 만든 retriever가 질문과 유사한 문서를 검색하고, 검색된 문서들은 {context}에 채워지며, 질문은 {question}에 채워져
최종적으로 하나의 프롬프트로 LLM (GPT-4o)에 전달됩니다.
💡 배운 점과 고민 포인트
✅ Chunking의 중요성
길이 단위로 Chunking을 진행하면 문서 중간 맥락이 끊길 수 있겠죠?
semantic chunking이나 요약 재작성 같은 기법을 다룰 수 있어야 함을 깨달았습니다 :)
✅ 검색 실패 대비
검색 결과가 없거나 정확도가 낮을 때를 대비해, "검색결과 없음" 으로 처리하는 것도 기본적인 실패 처리는 할 수 있겠지만,
reranking, BM25 혼합, Agent RAG 같은 강화 전략이 필요하다고 합니다.
✅ 멀티모달, 멀티턴 확장
이번 실습은 하나의 질문(여러 질문 요소가 담겨있을 수 있는)에, 유사한 결과, 연결된 정보들이 모두 답변되는 RAG 파이프라인이었는데요.
이미지나 표 데이터, 복잡한 다중 질의까지 처리하기 위해서는 멀티모달 LLM이나 별도의 처리 모듈 설계가 필요하다는 점도 인상 깊었습니다.
이번 강의에 포함된 내용이라하니, 열심히 들어야겠네요 :)
① 오늘자 날짜, 공부 시작, 종료 시각 포함 사진 각 1장


② 1개 클립 수강 인증 사진 1장 / 학습 인증 사진 1장
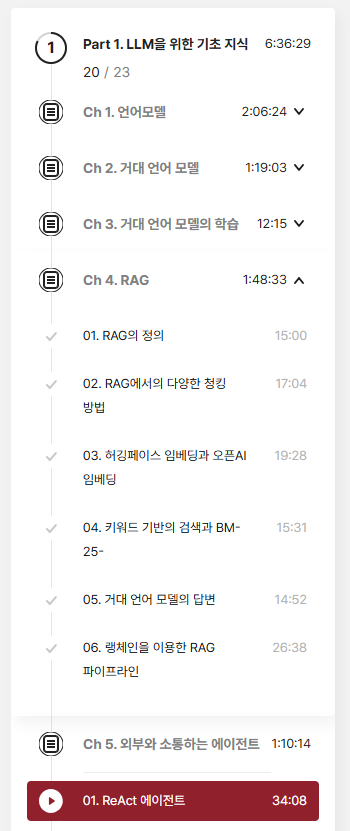

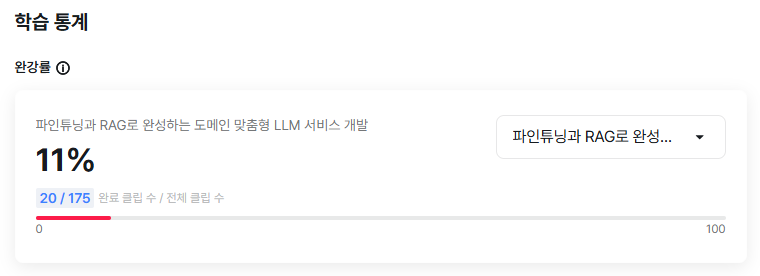
③ 챌린지 대상 강의 완강률 캡쳐 사진 1장
https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
'패스트캠퍼스환급챌린지' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 15일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (2) | 2025.07.15 |
|---|---|
| 패스트캠퍼스 환급챌린지 14일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (0) | 2025.07.14 |
| 패스트캠퍼스 환급챌린지 12일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (0) | 2025.07.12 |
| 패스트캠퍼스 환급챌린지 11일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (1) | 2025.07.11 |
| 패스트캠퍼스 환급챌린지 10일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (0) | 2025.07.10 |