※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. ※

오늘은 RAG(Retrieval-Augmented Generation)에서 중요한 기술 중 하나인 청킹(Chunking)에 대해 학습했습니다.
청킹은 말 그대로 긴 문서를 적절한 검색 단위로 잘게 나누는 작업입니다.
이렇게 잘린 조각들이 임베딩 단위로 Vector DB에 저장되며, 검색 후 LLM이 답변을 생성할 때 참조됩니다.
✂️ 여러가지 청킹 방법
1️⃣ 길이 단위 청킹
문서 길이에 따라 기계적으로 잘라내는 방식입니다.
RAG에서 사용되는 프레임워크 LangChain의 RecursiveCharacterTextSplitter라는 텍스트 분할기가 이 방식을 사용합니다.
간단하지만 문맥이 중간에 잘릴 수 있어 검색 성능이 저하될 가능성이 있다고 하네요.
2️⃣ 시맨틱 청킹
문맥을 이해하며 잘라내는 방식입니다.
LLM, T5, 임베딩 모델 등 작은 규모의 모델을 활용하거나, 사람이 직접 잘라낼 수도 있습니다.
특히, LLM을 직접 청킹에 활용하면 성능은 뛰어나지만 비용이 발생하게 되겠죠...?
3️⃣ Fine-tuned Model Based Chunker
두 문장이 연결되는지 아닌지를 학습한 모델로 판단해 자릅니다.
이는 LangChain의 단순 시맨틱 청커보다 훨씬 강력하다고 알려져 있습니다.
4️⃣ 합성 데이터 방식
은 문서를 잘라내는 대신 LLM에게 복잡한 문서를 여러 개로 재작성해달라고 요청하는 방식입니다.
각각의 재작성된 문서가 완결성을 가지므로 검색용으로 우수합니다.
5️⃣ 청킹 후 정제
는 이미 잘라낸 문서를 다시 다듬어 노이즈를 제거하는 단계입니다.
이를 통해 더 좋은 임베딩 품질을 확보할 수 있습니다.
🔧 허깅페이스 임베딩 실습
청킹에 대한 개념을 공부한 후에는, 허깅페이스에서 다운받은 임베딩과 OpenAI의 임베딩 API를 비교하는 실습을 진행해봤습니다.
Hugging Face의 경우, BAAI/bge-m3 임베딩 모델을 사용해봤습니다.
문장을 벡터화 하고, Pandas DataFrame에 저장한 뒤 코사인 유사도 함수를 통해 질문과 가장 유사한 문장 3개를 추출했습니다.

위의 결과와는 다르게, OpenAP의 API를 사용해서 임베딩을 진행했을 때는 보다 좋은 성능을 반영한 결과가 나왔습니다. 확실히 LLM을 활용할 때의 성능이 좋아보이네요.

📌 오늘의 정리
- 청킹은 RAG의 핵심적인 전처리 단계입니다.
- 단순 길이 자르기보다는 문맥 기반 시맨틱 청킹이나 Fine-tuned 청커를 쓰는 것이 성능에 유리합니다.
① 오늘자 날짜, 공부 시작, 종료 시각 포함 사진 각 1장


② 1개 클립 수강 인증 사진 1장 / 학습 인증 사진 1장

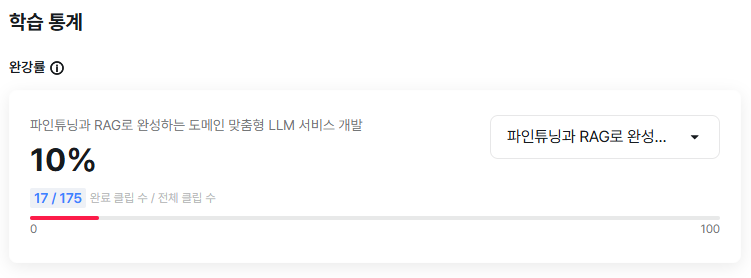
③ 챌린지 대상 강의 완강률 캡쳐 사진 1장

https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
'패스트캠퍼스환급챌린지' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 12일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (0) | 2025.07.12 |
|---|---|
| 패스트캠퍼스 환급챌린지 11일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (1) | 2025.07.11 |
| 패스트캠퍼스 환급챌린지 9일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.07.09 |
| 패스트캠퍼스 환급챌린지 8일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (0) | 2025.07.08 |
| 패스트캠퍼스 환급챌린지 7일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (1) | 2025.07.07 |