※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. ※

오늘은 허깅페이스를 통해 공개된 LLM을 사용할 때 필수로 고려해야 할 요소인 토크나이저와 템플릿 처리 방식, 그리고 파인튜닝(Fine-tuning)의 두 가지 주요 접근법에 대해 학습했습니다.
🧩 템플릿이 중요한 이유
LLM은 단순히 질문만 입력한다고 정확한 답변을 제공하지 않는다고 합니다.
모델은 사전에 학습된 프롬프트 형식(=템플릿)을 기준으로 입력을 해석하기 때문이죠.
tokenizer.apply_chat_template(messages, tokenize=False)
위처럼 tokenizer의 apply_chat_template()라는 메서드를 활용하면 불러온 모델에 알맞는 템플릿이 적용된 메세지의 모습을 확인 할 수 있습니다.
예를 들어, LLama3 모델은 다음과 같은 형식으로 구성되어있습니다.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
당신은 여행가이드입니다.<|eot_id|><|start_header_id|>user<|end_header_id|>
말레이시아 여행 일정 만들어줘<|eot_id|>
이처럼 모델마다 포맷이 다를 수 있기 때문에, 프롬프트 템플릿을 고려하지 않고 학습을 하면 성능 저하가 발생할 수 있습니다.
🔧 파인튜닝 전략: Full Fine-tuning vs PEFT (LoRA)
LLM을 특정 문제 해결을 위해 더 잘 활용하기 해서는 파인튜닝을 피할 수 없습니다...! 🤣
이는 사전 학습된 모델에 새로운 데이터를 추가로 학습시키는 과정으로, 두 가지 접근법이 존재합니다.
1. Full Fine-tuning
- 모델 전체 파라미터를 업데이트합니다.
- 가장 높은 성능 향상이 가능하지만, 자원 요구량이 큽니다.
- 수천억 개 파라미터를 조정하려면 막대한 GPU 메모리와 시간이 소요됩니다.
- 또한, 기존 모델이 가지고 있던 능력이 손상될 가능성
(멋진 자동차를 만들기 위해 부품을 전부 갈아끼운 다면...?)도 존재합니다.
2. PEFT (Parameter-Efficient Fine-Tuning)
- 모델 전체가 아닌 일부 파라미터만 조정합니다.
- 대표 기법으로는 LoRA (Low-Rank Adaptation)가 있습니다.
- 예를 들어, 1억 개의 파라미터를 가진 모델이 있다면 LoRA는 그 중 0.16% 수준만 학습하여 유사한 성능을 달성할 수 있습니다.
이러한 파인튜닝 방식은 모델을 설계하고 학습시키기 어려운 개인 개발자나 스타트업 환경에서 매우 유용할 수 있을 것 같네요 :)
게다가 원본 모델의 지식을 보존하면서 새로운 기능만 추가할 수 있다니... 응용할 수 있는 부분이 많을 것 같다는 생각이 듭니다.
📌 오늘의 정리
- LLM 사용 시, 모델에 맞는 템플릿 구조를 지키는 것이 중요합니다.
- 파인튜닝은 전체를 조정하는 'Full Fine-tuning'방식과, 일부만 조정하는 'PEFT(Parameter-Efficient Fine-Tuning)' 방식으로 나뉩니다.
- 성능, 비용 등을 고려하여 전략적으로 선택해야 합니다.
① 오늘자 날짜, 공부 시작, 종료 시각 포함 사진 각 1장


② 1개 클립 수강 인증 사진 1장 / 학습 인증 사진 1장


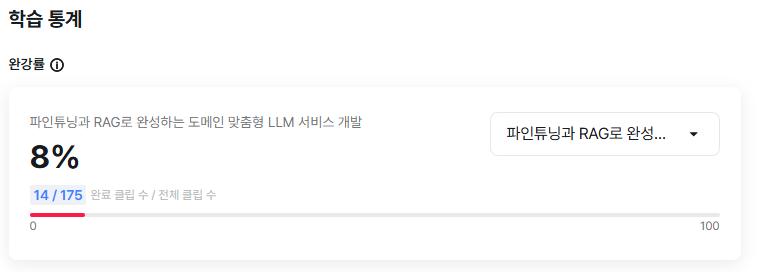
③ 챌린지 대상 강의 완강률 캡쳐 사진 1장
https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
'패스트캠퍼스환급챌린지' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 10일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (0) | 2025.07.10 |
|---|---|
| 패스트캠퍼스 환급챌린지 9일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.07.09 |
| 패스트캠퍼스 환급챌린지 7일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (1) | 2025.07.07 |
| 패스트캠퍼스 환급챌린지 6일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (4) | 2025.07.06 |
| 패스트캠퍼스 환급챌린지 5일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.07.05 |