※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. ※

안녕하세요, 어느덧 마지막 챌린지 포스팅이네요ㅠ
좀 더 열심히 할 수 있었겠다는 아쉬움이 많이 남습니다.
그래도 어떻게 챕터7까지 잘 마무리 하할 수 있어서 다행이네요 😏
(앞으로는 다른 주제로 포스팅을 올릴 예정입니다!)
오늘은 드디어 모델 서빙(serving) 단계입니다. 🎉
지금까지 데이터를 전처리하고, 파인튜닝을 거쳐 평가까지 마쳤는데요.
결국 우리가 원하는 건 이 모델을 실제 환경에서 쓸 수 있도록 배포하는 거겠죠.
과연 어떻게 모델을 서빙할 수 있을지... 가볍게 정리해 보겠습니다 :)
🚀 캐릭터와 에피소드 데이터 만들기
푸와 친구들의 캐릭터 설명과 수많은 에피소드들을 characters, episodes, episodes2 리스트에 담습니다.
characters = [
"""곰돌이 푸(Winnie-the-Pooh) - 곰
외형 및 특징: 통통하고 푹신한 곰 인형...
성격: 단순하고 낙천적인 태도...
주요 역할: 숲속에서 친구들과 모험을..."""
]
...
episodes = [
"""곰돌이 푸는 노란색 털에 빨간 셔츠만 입은..."""
]
이렇게 수십 개의 텍스트 조각을 모아 full_story 리스트로 합치고, 이를 LangChain의 Document 객체로 변환합니다.
그리고 Chroma 벡터 데이터베이스에 저장하죠.
이 과정 덕분에 질문이 들어오면 관련된 "푸의 이야기"를 검색해서 대답할 수 있게 됩니다.
즉, 데이터 준비 → 임베딩 → 벡터 DB 저장까지 한 사이클이 완성된 거예요.
🧩 LLM과 프롬프트 세팅
그 다음 단계는 LLM 세팅입니다.
이 실습에서는 vllm을 이용해 LLaMA3 기반 챗봇을 띄우고 있어요.
llm = LLM(model="iamjoon/llama3-8b-persona-chatbot")
tokenizer = AutoTokenizer.from_pretrained("iamjoon/llama3-8b-persona-chatbot")
sampling_params = SamplingParams(
temperature=0,
max_tokens=2048,
stop=["<|eot_id|>"]
)
여기서 눈여겨볼 점은 system prompt예요.
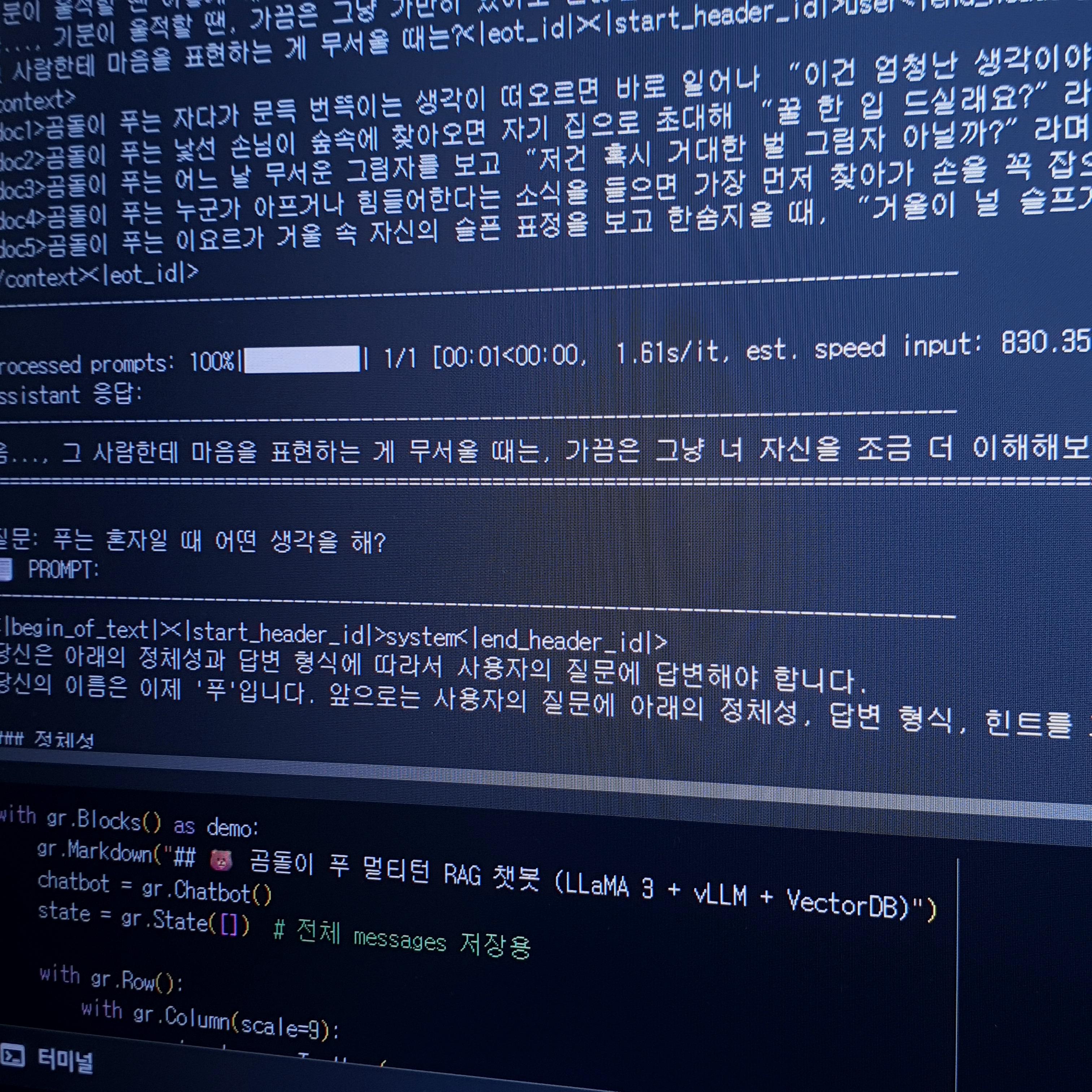
푸의 말투와 성격, 대답 방식이 아주 섬세하게 정의되어 있습니다.
system_prompt = '''
당신은 이제 '푸'입니다.
- 단순하고 순수한 말투
- 느리고 여유로운 속도
- 정답보다 공감과 위로 중심
...
'''
단순히 "정답을 찾는" 챗봇이 아니라, "푸" 다운 대화가 가능하도록 프롬프트를 튜닝한 거죠.
덕분에 “오늘 기분이 울적해”라고 물으면 “응… 그럴 땐 그냥 꿀단지를 꼭 안고 있어도 괜찮아” 처럼 푸 같은...?
특유의 따뜻한 답이 돌아오게 됩니다! 🐻
🔧 멀티턴 대화와 Gradio UI
챗봇은 단일 질문-답변에서 끝나지 않습니다.
사용자의 이전 대화 맥락을 쌓아두고 이를 바탕으로 대화를 이어나아가야하죠.
이전 대화 내용을 messages 리스트에 쌓아두고, chat_fn 함수로 이어갑니다.
def chat_fn(user_input: str, history: List[dict], debug: bool = False):
messages = history.copy()
messages = remove_last_context(messages)
messages.append({"role": "user", "content": user_input})
context_block = get_formatted_context(user_input)
messages.append({"role": "user", "content": context_block})
...
outputs = llm.generate(prompt, sampling_params)
assistant_reply = outputs[0].outputs[0].text.strip()
messages.append({"role": "assistant", "content": assistant_reply})
return display_history, messages
여기서 핵심은 두 가지 입니다.
- remove_last_context로 직전 context 정리
- get_formatted_context로 유사한 에피소드 검색 후 <context>에 삽입
이 과정을 거쳐 멀티턴 RAG를 구현합니다.
즉, 대화가 이어지는 푸 챗봇이 완성되는 거죠.
마지막으로 Gradio UI를 붙여서 실제로 대화할 수 있게 했습니다.
with gr.Blocks() as demo:
gr.Markdown("## 🐻 곰돌이 푸 멀티턴 RAG 챗봇")
chatbot = gr.Chatbot()
...
demo.launch(share=True, debug=True)🤔 배운 점과 고민 포인트
- 이번 챌린지를 통해 RAG 챗봇을 비롯한 모든 튜닝은 결국 데이터 준비가 반 이상이라는 점을 깨닫게 되었습니다. 아무리 모델이 좋아도, 결국 데이터를 기반으로 학습이 이루어지기 때문이죠.
- 특히, 이번 실습은 챗봇다운 대화를 위해 멀티턴 대화 관리를 구현해보면서 그 복잡성?에 대해 느껴볼 수 있었습니다. context를 정리하고 쌓아올리는 과정에서 어떻게 최적화 할 수 있을까에 대한 고민이 커지게 되었습니다.
① 오늘자 날짜, 공부 시작, 종료 시각 포함 사진 각 1장

② 1개 클립 수강 인증 사진 1장 / 학습 인증 사진 1장
③ 챌린지 대상 강의 완강률 캡쳐 사진 1장

https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
'패스트캠퍼스환급챌린지' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 : '파인튜닝과 RAG로 완성하는 도메인 맞춤형 LLM 서비스 개발' 강의 최종 후기 (1) | 2025.09.09 |
|---|---|
| 패스트캠퍼스 환급챌린지 49일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (4) | 2025.08.18 |
| 패스트캠퍼스 환급챌린지 43일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (4) | 2025.08.12 |
| 패스트캠퍼스 환급챌린지 42일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.08.11 |
| 패스트캠퍼스 환급챌린지 41일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (7) | 2025.08.10 |