※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. ※

오늘은 지난 시간에 이어서 곰돌이 푸 페르소나 챗봇 데이터셋에서 마지막 단계인 검색 기반 RAG 데이터 생성 작업을 진행했습니다.😏
이 단계는 단순히 대화를 만들어주는 것이 아니라, 검색된 문서를 참고해서 답변을 생성하는 구조를 학습 데이터에 녹이는 과정이기 때문에
이전에 생성했던 싱글턴, 멀티턴 데이터와 통합하여 좀 더 풍부한 학습 효과를 챙길 수 있게 됩니다 :)
🔍 검색 기반 응답 설계
먼저, 기존에 만들어 둔 질문 리스트에서 하나씩 꺼내 벡터 검색을 수행했습니다.
OpenAIEmbeddings을 사용해 질문과 문서를 숫자 벡터로 변환했고,
Chroma 벡터스토어에서 상위 5개의 연관 문서를 찾도록 했습니다.
embedding = OpenAIEmbeddings()
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=embedding)
docs = vectorstore.similarity_search(question, k=5)
이렇게 얻은 docs 값은 단순 참고용이 아니라, 곰돌이 푸가 답변할 때 컨텍스트로 바로 넣어줬습니다.
검색 결과를 제공하지 않으면 모델이 없는 내용을 지어낼(할루시네이션) 위험이 있으니까요 😉
⚙️ 응답 생성과 필터링
OpenAI Chat API를 사용해 응답을 만들었고, 생성된 답변은 다시 한번 검토했죠.
말투가 어긋나거나, 검색 결과와 전혀 관련 없는 내용이 포함되면 제외했습니다.
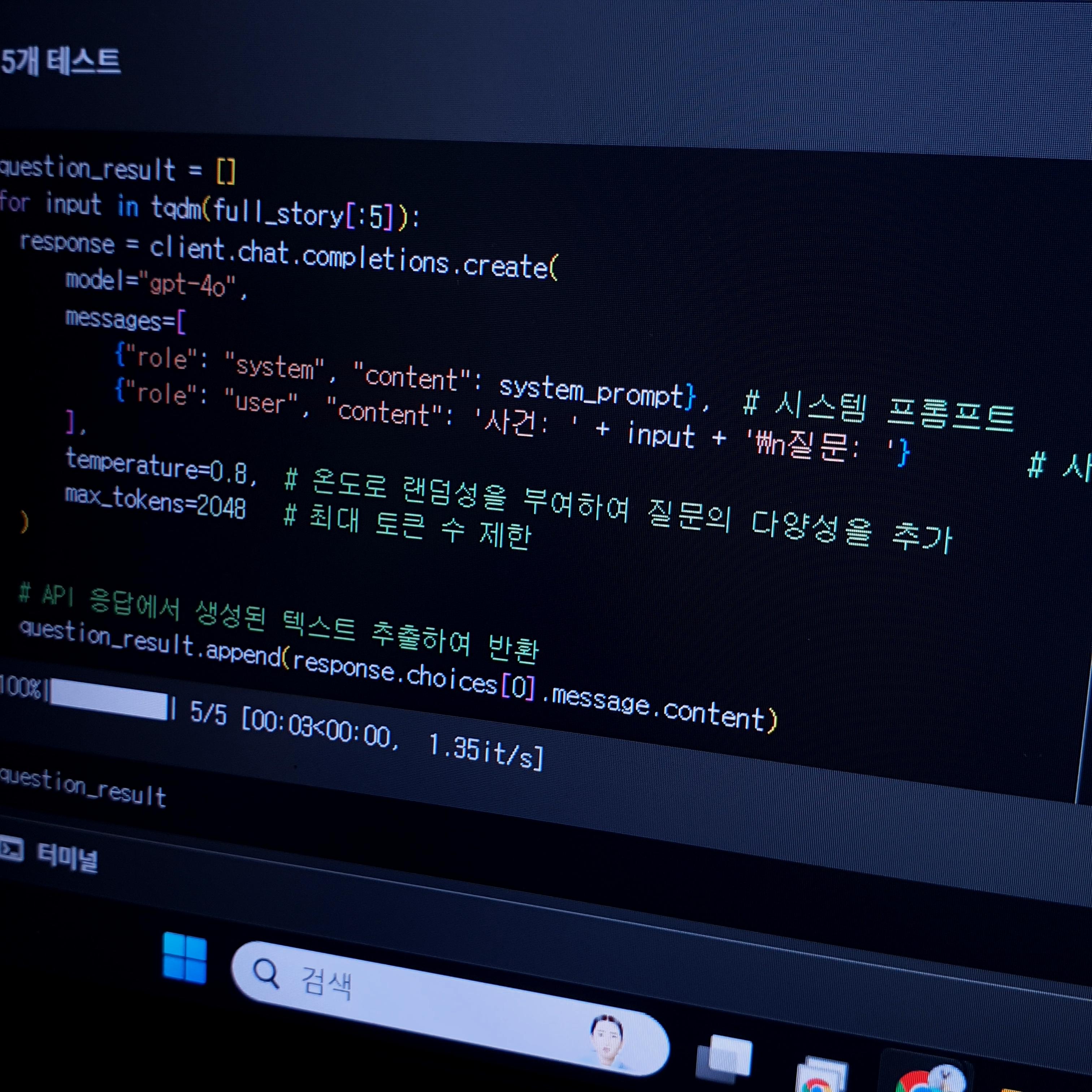
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
)
이 필터링 과정이 중요한 이유는, 잘못된 응답까지 학습 데이터로 들어가면 모델이 잘못된 패턴을 그대로 학습하기 때문입니다.
📦 데이터 통합과 업로드
검색 기반 데이터가 완성되면, 기존의 싱글턴 대화 데이터와 멀티턴 대화 데이터에 합쳤습니다.
그 후 datasets.Dataset.from_list()로 합친 데이터를 Hugging Face 허브에 업로드 합니다.(이번 실습에서는 업로드 하지 않고, 강사님 모델 사용 예정)
from datasets import Dataset
Dataset.from_list(final_data).push_to_hub("my-pooh-dataset")이렇게 해두면 나중에 파인튜닝 단계에서 바로 불러와서 사용할 수 있어 편리합니다.
🤔 배운 점과 고민 포인트
✨ 배운 점
- 검색 결과를 어떤 순서와 방식으로 프롬프트에 넣는지에 따라서 응답 품질을 좌우한다는 점을 깨달음
① 오늘자 날짜, 공부 시작, 종료 시각 포함 사진 각 1장


② 1개 클립 수강 인증 사진 1장 / 학습 인증 사진 1장
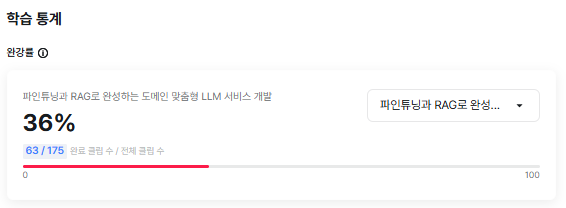
③ 챌린지 대상 강의 완강률 캡쳐 사진 1장
https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
'패스트캠퍼스환급챌린지' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 49일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (4) | 2025.08.18 |
|---|---|
| 패스트캠퍼스 환급챌린지 43일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (4) | 2025.08.12 |
| 패스트캠퍼스 환급챌린지 41일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (7) | 2025.08.10 |
| 패스트캠퍼스 환급챌린지 40일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (5) | 2025.08.09 |
| 패스트캠퍼스 환급챌린지 39일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.08.08 |