※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. ※

오늘은 LoRA를 활용해 LLaMA 모델을 직접 학습시키고 테스트하는 전 과정을 마무리했습니다.
역시나 익숙하다고 할 수는 없지만, 4주차에 접어들었다고 조금씩 들리고 이해가 되기 시작했어요. 😏
🧠 SFTTrainer로 파인튜닝 학습 시작하기
파인튜닝의 핵심 단계는 아무래도 모델을 학습하는 거겠죠.
본 실습에서는 SFTTrainer를 호출하여 학습을 진행했습니다.
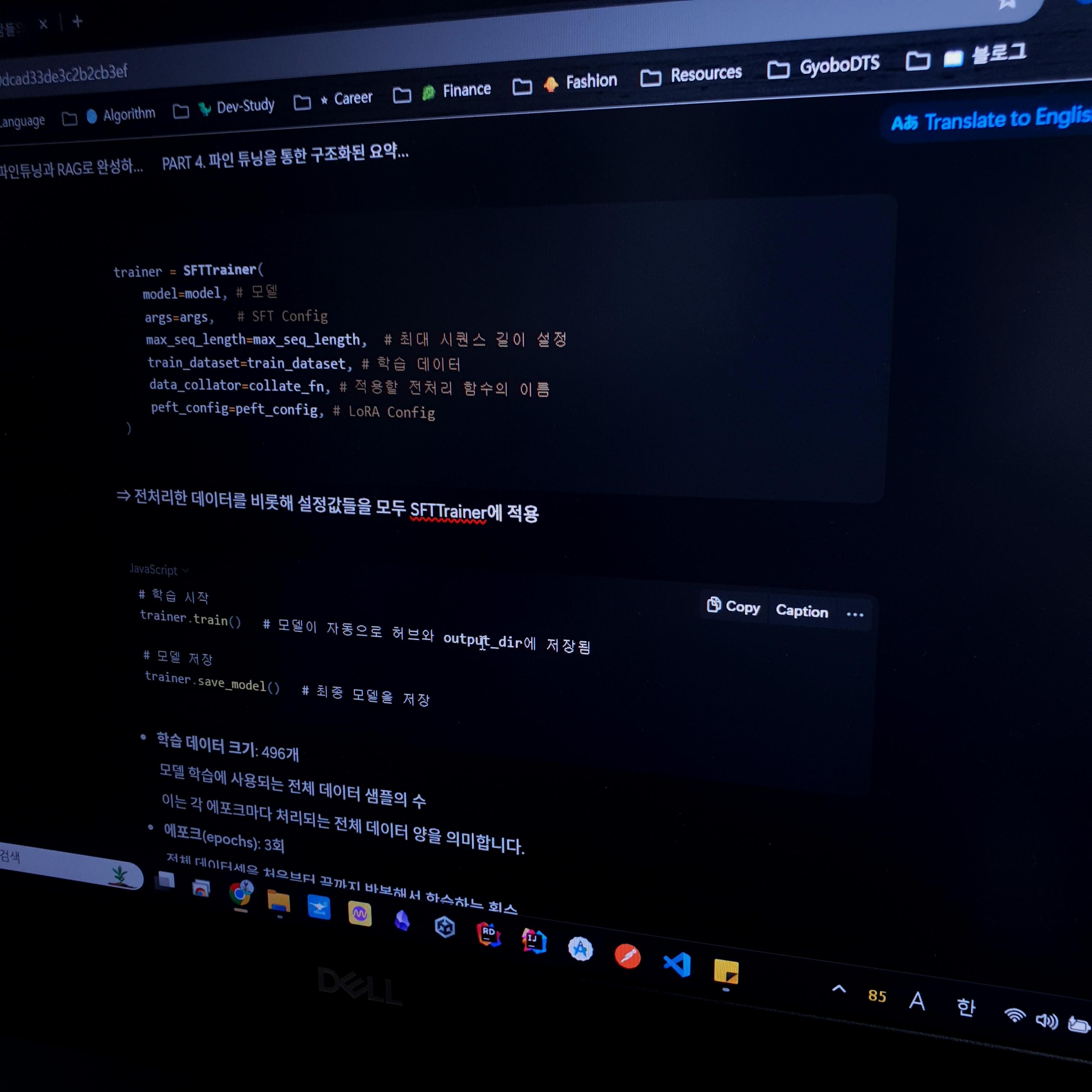
trainer = SFTTrainer(
model=model,
args=args,
max_seq_length=max_seq_length,
train_dataset=train_dataset,
data_collator=collate_fn,
peft_config=peft_config,
)이전까지 준비한 모든 설정값(모델, 하이퍼파라미터, 데이터셋, 전처리 함수, LoRA Config)들을 SFTTrainer 이 한 곳에 통합을 합니다. 그리고 이를 바탕으로 파인튜닝을 하게 되죠.
# 학습 시작
trainer.train() # 모델이 자동으로 허브와 output_dir에 저장됨
# 모델 저장
trainer.save_model() # 최종 모델을 저장
🔢 학습 구조 분석
학습을 진행시켰을 때, 전체 업데이트 수가 372개로 나왔습니다.
왜 372개가 나오는 지에 대해 궁금했는데요.
다행이도 강의를 통해 이 부분에 대해 꼼꼼히 설명을 들을 수 있었습니다.
우선, 주어진 학습 데이터 샘플 수가 496개였습니다.
배치 크기와 누적스텝은 각각 2로 총 4번개의 학습 데이터가 한번에 처리될거에요.
그럼 에포크 당 업데이트 수는 124개가 되게 됩니다. (496 / 4 = 124)
주어진 에포크 수는 3이므로, 124 * 3을 하여 372번의 업데이트 수가 산정되는 것이죠.
배치는 한 번에 처리하는 데이터 샘플의 수입니다.
배치 크기를 크게 가져가야 학습이 잘된다고 통상적으로 알려져 있으나, 자원(GPU 메모리)의 제한이 있을 수 있고
너무 큰 배치 크기는 에러와 함께 학습 중단을 낼 수 있죠.
그래서 종종 메모리 효율을 위해 전체 데이터를 작은 배치로 나누어 처리하며, 본 실습에서는 2개씩 묶어서 처리했던 것입니다.
'그럼 배치의 크기가 작아지니 학습이 잘 안되지 않을까?' 라는 생각을 가져볼 수도 있겠죠.
이때 누적 단계(Accumulation steps)의 힘이 발휘됩니다 😊
누적 단계란, 모델을 실제로 업데이트하기 전에 여러 배치의 정보를 모으는 수인데요.
여기서는 2개의 배치(총 4개의 샘플)를 처리한 후에야 실제 모델 업데이트가 일어납니다.
배치가 작아도 accumulation steps를 통해 배치가 커지는 효과를 얻을 수 있는 것이죠 😗
🧠 파인튜닝된 모델 로드 및 테스트
아래 코드를 통해 LoRA Adapter와 LLM이 결합된 완성형 모델을 로드합니다:
from peft import AutoPeftModelForCausalLM
peft_model_id = "llama3-8b-summarizer-ko/checkpoint-372"
fine_tuned_model = AutoPeftModelForCausalLM.from_pretrained(peft_model_id, device_map="auto", torch_dtype=torch.float16)
그리고 HuggingFace pipeline으로 텍스트 생성 파이프라인을 생성합니다:
추가로, LLM의 답변 생성을 중단(종료)시키기 위해서는 종료 토큰을 넣어주어야하기 때문에 eos_token이라는 이름으로 종료 값(템플릿에 따라 다를 수 있음)을 담아 pipe()에 설정해줍니다.
pipe = pipeline("text-generation", model=fine_tuned_model, tokenizer=tokenizer)
eos_token = tokenizer("<|eot_id|>", add_special_tokens=False)["input_ids"][0]
# 결과 확인 함수
def test_inference(pipe, prompt):
outputs = pipe(prompt, max_new_tokens=1024, eos_token_id=eos_token, do_sample=False)
return outputs[0]['generated_text'][len(prompt):].strip()
그리고 이렇게 파인튜닝된 모델은 파인튜닝 되기전의 기본 모델과 생성한 답변을 비교하여 그 결과를 비교해보았습니다.
base_model_id = "NCSOFT/Llama-VARCO-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(base_model_id, ...)
그 결과는...!
파인튜닝된 모델이 훨씬 더 자연스럽고 완결된 응답을 생성하여 성공적! 이었다고 볼 수 있겠습니다.
기본모델은 json을 생성한 후, 추가적인 설명 텍스트를 생성하는 등, 데이터 완결성이 다소 부족했거등요...!
🤔 배운 점과 고민 포인트
📘배운 점
- SFTTrainer와 LoRA를 활용해 LLM 학습 구조에 대한 이해.
- accumulation_steps를 활용한 메모리 효율적인 학습 전략에 대한 이해를 할 수 있었음.
① 오늘자 날짜, 공부 시작, 종료 시각 포함 사진 각 1장


② 1개 클립 수강 인증 사진 1장 / 학습 인증 사진 1장
③ 챌린지 대상 강의 완강률 캡쳐 사진 1장

https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
'패스트캠퍼스환급챌린지' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 30일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (6) | 2025.07.30 |
|---|---|
| 패스트캠퍼스 환급챌린지 29일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (2) | 2025.07.29 |
| 패스트캠퍼스 환급챌린지 27일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (4) | 2025.07.27 |
| 패스트캠퍼스 환급챌린지 26일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.07.26 |
| 패스트캠퍼스 환급챌린지 25일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (1) | 2025.07.25 |