※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. ※

오늘부터는 PART4 중 두번째 실습, '허깅페이스 TRL을 활용한 파인튜닝' 강의를 듣기 시작했습니다 : )
첫 강의를 들었는데요.
실제 실습을 진행하기 전에 전체 코드를 훑어보며 놓칠 수 있었던 포인트들을 짚어주는 내용이었고,
실습에 앞서 예습과 지난 실습의 복습을 동시에 할 수 있었던 시간이었습니다.
이번 강의를 통해 파인튜닝의 핵심 개념과 데이터 전처리에 대해 다시 한번 점검하고,
다음 실습에 대비할 수 있는 중요한 포인트들을 정리했습니다.
🔍 파인튜닝을 위한 기본 설정
강의에서 다룬 첫 번째 중요한 내용은 학습 데이터 준비입니다.
우리는 HuggingFace 데이터셋을 로드하고, 이를 학습용 데이터와 테스트용 데이터로 50:50 비율로 분할했습니다.
이 때, 데이터 전처리 과정에서 OpenAI 형식에 맞게 데이터를 변환하는 부분이 핵심이었습니다.
# OpenAI format으로 데이터 변환
def format_data(sample):
return {
"messages": [
{"role": "system", "content": sample["system_prompt"]},
{"role": "user", "content": sample["user_prompt"]},
{"role": "assistant", "content": str(sample["assistant"])}
]
}
왜 학습데이터와 테스트 데이터를 50:50으로 분할했는지, 의문을 가지시는 분들이 있을 수 있겠는데요.
통상적으로는 학습데이터가 테스트보다 비율이 높도록(70:30 정도?) 분할하지만, 유료 GPU 컨테이너 서비스 RunPod을 사용하는 만큼,
학습시간을 최소화하지만 튜닝 결과는 챙겨야 했기에... 선택한 분할 비율... 이라고 할 수 있겠습니다. 하핳 😂
이후, 각 샘플을 role-based 형식으로 변환했고, 이는 실제 LLM 서비스에서 입력과 출력을 정의할 때 매우 중요한 부분입니다.
프롬프트 형식이 제대로 준비되지 않으면 모델이 제대로 학습하지 못하기 때문이죠!
🛠️ LoRA 튜닝 및 SFTConfig 설정
LoRA(Low-Rank Adaptation) 튜닝 설정을 살펴봤습니다.
LoRA는 기본 모델의 파라미터를 일부만을 수정하여 효율적으로 파인튜닝하는 기법인데, 속도와 메모리 효율성을 크게 향상시킬 수 있습니다.
peft_config = LoraConfig(
lora_alpha=32,
lora_dropout=0.1,
r=8,
bias="none",
target_modules=["q_proj", "v_proj"],
task_type="CAUSAL_LM"
)
위 코드에서처럼 lora_alpha, r 등의 하이퍼파라미터를 설정하면서 LoRA 튜닝을 준비합니다.
많은 설정 값 중에서, lora_alpha, r 값이 학습에 영향을 많이 준다고합니다.
하지만, 보통 학습데이터의 영향이 더 크므로 학습 결과가 맘에 들지않는다고 해서 설정값을 바꾸고 학습만을 반복하는 것 보다는
학습 데이터의 오류, 양 등을 최우선으로 고려해야 할 필요가 있다는 좋은 팁을 배울 수 있었습니다 😎
그 다음, SFTConfig를 통해 전체 학습 설정을 정의합니다.
SFTConfig는 풀파인튜닝을 하든 로라튜닝을 하든 설정을 해줘야하며
모델 저장 위치, 에포크 수, 배치 크기 등 학습과 관련된 모든 설정을 조정하게 됩니다.
args = SFTConfig(
output_dir="llama3-8b-summarizer-ko",
num_train_epochs=3,
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
gradient_checkpointing=True,
optim="adamw_torch_fused",
logging_steps=10,
save_strategy="steps",
save_steps=50,
bf16=True,
learning_rate=1e-4,
max_grad_norm=0.3,
warmup_ratio=0.03,
lr_scheduler_type="constant",
report_to=None
)
이와 같이 SFTConfig는 모델 학습 시 필수적으로 설정해야 하는 매개변수들을 조정하며,
학습률, 에포크, 저장 주기 등을 명확히 지정해줍니다.
이 부분도 각 설정값들이 어떤 역할을 하는지, 실습 전에 한번쯤 체크해봐야할 부분이었습니다.
💡 배운 점과 고민 포인트
오늘 강의는 실습을 대비하는 중요한 예습 시간이었습니다.
데이터 포맷을 제대로 준비하고, LoRA 튜닝 및 SFTConfig에서 세부 설정을 하는 과정이 매우 중요함을 느꼈습니다.
아직 학습 결과를 바탕으로 어떤 결과가 잘 학습된 모델이지, 잘 학습되지 않은 모델인지는 경험하지 못했지만, 훑어본 설정값들을 바탕으로 체크해볼 수 있는 지점이 생겼다는 것에 의의가 있는 것 같습니다.
내일 실습을 진행하면서 이론을 코드로 직접 타이핑 해보고, 학습을 돌려보면서
실제 파인튜닝을 진행하는 데 중요한 포인트를 꼼꼼히 짚어보도록 하겠습니다 :)
① 오늘자 날짜, 공부 시작, 종료 시각 포함 사진 각 1장


② 1개 클립 수강 인증 사진 1장 / 학습 인증 사진 1장

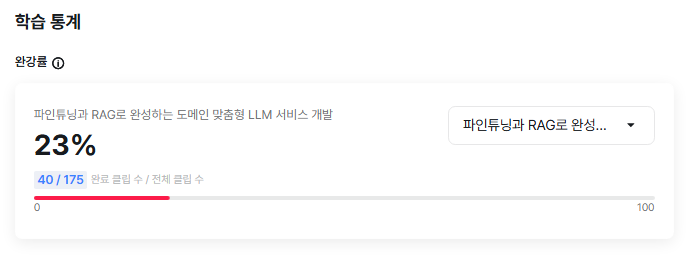
③ 챌린지 대상 강의 완강률 캡쳐 사진 1장
https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
'패스트캠퍼스환급챌린지' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 28일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.07.28 |
|---|---|
| 패스트캠퍼스 환급챌린지 27일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (4) | 2025.07.27 |
| 패스트캠퍼스 환급챌린지 25일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (1) | 2025.07.25 |
| 패스트캠퍼스 환급챌린지 24일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.07.24 |
| 패스트캠퍼스 환급챌린지 23일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (6) | 2025.07.23 |