※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. ※

AI에 많은 사람들이 주목하고 있습니다. 알음알음 공부해보기도 하고 사용해보기도 했지만, 제대로 공부해봤다고 말할 수는 없었죠.
그래서 LLM에 대해 공부를 시작해보겠다 다짐했습니다. 그리고 우연찮게 '패스트캠퍼스'에서 시작한 환급 챌린지가 눈이 들어왔죠.
덕분에 이렇게 티스토리에 블로그까지 써보게 됩니다.
앞으로 50일간, "파인튜닝과 RAG로 완성하는 도메인 맞춤형 LLM 서비스 개발" 강의를 들으며, 다소 빈약하더라도 이런 저런 글을 써보려고 합니다.
감사합니다 :)
언어모델은 무엇을 ‘언어’라고 부를까?
인공지능은 정말 사람의 말, 자연어를 이해할까요?
보는 시각에 따라 의견은 다양하겠지만 사실, LLM(Large Language Model)은 ‘이해’보다는 ‘예측’에 가까운 일을 합니다.
즉, 주어진 문장 속에서 다음에 등장할 확률이 가장 높은 단어(token)를 찾아내는 것. 우리 인간이 사고하고 이해하는 모습과는 사뭇 다르죠.
그럼에도 불구하고, 놀라운 점은 이렇게 단어를 예측하는 AI 모델이 소설을 쓰고, 이메일을 정리하기도 하며, 프로그래밍까지 한다는 점입니다.
디코더 GPT
자연어 처리(NLP)의 진화 과정을 보면, 마치 인간의 언어 습득 단계를 보는 듯합니다.
초기에는 단순히 패턴과 규칙에 기반한 통계 기반 모델에서 문장의 흐름(RNN 계열의 순환 신경망)을 고려하게 되고, 트랜스포머의 등장으로 문맥간의 관계를 고려하며 다음 단어를 내뱉게 되었죠.
요즘 거의 모든 LLM의 뿌리, 트랜스포머(Transformer)는 2017년 구글이 발표한 논문 “Attention is all you need”을 통해 세상에 공개되었습니다.
이 모델은 크게 인코더(문장을 이해, NLU, Natural Language Understanding), 디코더(문장을 생성, NLG, Natural Language Generation)로 나뉘게 됩니다.
아마 다음 강의를 듣다 보면 더 공부하게 되겠지만,
BERT는 인코더, GPT는 디코더의 구조만을 계승했고, T5/BART는 인코더-디코더 구조를 모두 유지한채로 발전해나아가고 있다고합니다.
어쩌면, GPT가 “창작”에 강한 이유도 여기 있겠네요. 한 단어씩 ‘다음에 나올 말’을 예측하며 생성해나아가는 방식 말이죠.
번역기에서 세상의 언어를 이해하는 모델로
최초의 트랜스포머는 구글 번역기의 성능을 향상시키기 위해 고안되었다고 합니다.
그러나 지금은 이 구조를 바탕으로 수십억 개의 문서로 학습된 모델이 말 그대로 세상을 뒤흔들고 있습니다.
GPT 시리즈는 생성형 서비스에 강점을 보이며, 자연스러운 챗봇 서비스를 구현해냈고
BERT는 검색, 질의응답 시스템, 텍스트 분류 분야에서 지금도 널리 쓰인다고 합니다.
오늘날의 LLM은 단순한 ‘다음 단어 예측기’를 넘어섰습니다.
앞으로 10년 뒤, 아니 1년 뒤의 LLM의 모습은 어떠할까요?
① 오늘자 날짜, 공부 시작, 종료 시각 포함 사진 각 1장


② 1개 클립 수강 인증 사진 1장 / 학습 인증 사진 1장

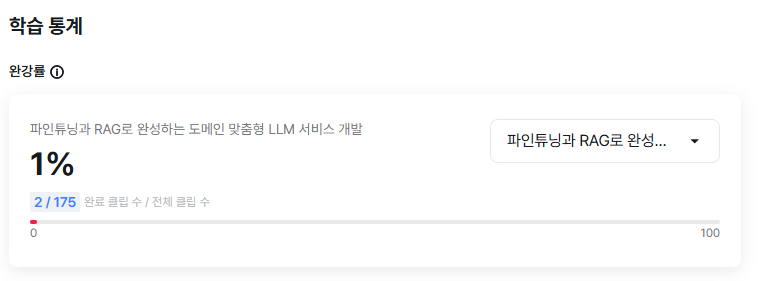
③ 챌린지 대상 강의 완강률 캡쳐 사진 1장
https://fastcampus.info/4n8ztzq
(~6/20) 50일의 기적 AI 환급반💫 | 패스트캠퍼스
초간단 미션! 하루 20분 공부하고 수강료 전액 환급에 AI 스킬 장착까지!
fastcampus.co.kr
'패스트캠퍼스환급챌린지' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 6일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (4) | 2025.07.06 |
|---|---|
| 패스트캠퍼스 환급챌린지 5일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.07.05 |
| 패스트캠퍼스 환급챌린지 4일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (1) | 2025.07.04 |
| 패스트캠퍼스 환급챌린지 3일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (1) | 2025.07.03 |
| 패스트캠퍼스 환급챌린지 2일차 : 파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발 강의 후기 (3) | 2025.07.02 |